文凱認為,大規模神經網絡是AI未來發展趨勢,而量子計算“必能破局”,因為量子計算具有算力、存儲、帶寬、容錯四大方面的優越性。

本文來自: 謝矩題圖來自“外部授權”
9月27日,2021年中國國際信息通信展覽會(PT展)在北京正式開幕。PT展由工業和信息化部主辦,是泛ICT行業最具行業影響力的展會之一。
在開幕當日舉辦的量子計算專題論壇上,玻色量子創始人&CEO文凱發表了以《走向AI時代的量子計算》為主題的演講。他在演講中表示:“自從深度學習被提出以來,深度學習參數的高速提升和大規模神經網絡等都是AI快速發展的直接表現。量子計算可以解決AI快速發展所帶來的算力、帶寬、存儲空間等不夠的問題,同樣的人工智能也可以為量子計算解決容錯率低的問題。”
文凱將量子計算的發展分為四大階段:
第一階段為1981~1993年,是理論提出及探索階段,主要物理學家有保羅·貝尼奧夫、理查德·費曼、大衛·德依奇(Deutsch算法提出者)。
第二階段為1994~2009年,是通用量子算法發展階段,主要物理學家有shor算法提出者彼特·肖爾、Grover算法提出者羅夫·格羅弗和HHL算法提出者阿蘭·哈羅、阿維那坦·哈西迪、賽思·羅伊德,物理學家們就開始了不同物理體系單比特和兩比特量子計算實驗驗證。
第三階段為2010~2017年,是近期量子算法繁榮階段,以谷歌、IBM為代表的企業開始進行規模化量子計算機實驗工程化。
第四階段為2018年至今,是量子AI爆發階段。
量子計算目前處于技術研究、樣機研發與應用探索的關鍵階段,在學術界和產業界多方推動下獲得迅速發展。2020年12月,我國科學家成功構建76個光子的量子計算原型機“九章”,再次實驗驗證“量子優越性”。
在IBM、Honeywell和lonQ等公司的推動下,超導和離子阱等技術路線樣機的量子體積指標進一步提升。在化學、金融、交通等領域,量子計算的潛在應用探索加速。量子計算受到社會輿論和資本市場的持續關注,對技術和產業形成良性激勵,量子計算進入技術攻堅與應用探索的“黃金時期”。
在此背景下,國內外諸多科技企業和初創企業紛紛布局,包括IBM、Google、Amazon、Microsoft、D-wave、lonQ、Reggeti、華為、阿里、百度、騰訊、本源、量旋、啟科等,紛紛發布和推出量子計算處理器和原型機、量子計算軟件和開發工具,以及量子云計算服務等。量子計算的應用探索、產業培育和生態構建正逐步展開。
文凱認為,大規模神經網絡是AI未來發展趨勢,而量子計算“必能破局”,因為量子計算具有算力、存儲、帶寬、容錯四大方面的優越性:
1、算力優越性:量子的疊加態,使得量子計算具有對求解問題的指數級并行算力加速。
2、存儲優越性:量子神經網絡的容量可以遠超于經典神經網絡,用指數級量子存儲模型,可以用1200個量子比特存儲GPT3的整個網絡模型。在一定的算法下,數據也可以用量子模型存儲,節省存儲空間。
3、帶寬優越性:在國家東數西算大背景下,帶寬成為算力瓶頸,這些瓶頸不僅來自神經網絡,還有內存和緩存的帶寬。量子計算數據和模型的存儲壓縮,可以指數級優化帶寬。
4、容錯優越性:中短期之內,在糾錯還沒有做到100%精準的情況下,可以利用量子神經網絡的魯棒性和容錯性來實現對沖。
文凱將當前面向神經網絡的量子計算架構分為三種:IBM和谷歌正在研發的門電路通用量子計算、D-Wave的量子退火計算,以及玻色量子自主研發的相干量子計算。”
前兩者在共同點上都需要真空超低溫稀釋制冷機的環境控制,體積較為龐大。在文凱看來,玻色量子自主研發的光量子技術路線,通過對激光的精準控制,不需要超低溫超導環境,在室溫下即可運行,具有穩定的狀態,穩定的操控,和穩定的結果“三穩”優勢。
同時,文凱表示,玻色量子的“相干量子計算方案”是已實現的比特數規模最大的技術方案,也是主流方案中有望最快實現百萬量子比特規模的方案之一。在商業化應用場景上,能在成本、功耗可控的條件下,即刻解決當下許多需要使用超大算力加速的問題。
以下為文凱的演講全文:

(玻色量子創始人、CEO文凱/來源:2021中國國際信息通信展覽會)
大家好,我是北京玻色量子科技有限公司的創始人、CEO文凱。我今天給大家分享量子計算走向AI時代的歷程,給大家簡單介紹一下量子計算的發展史,同時再介紹跟人工智能的關聯。
說到量子計算,現在大家都覺得是一個非常前沿的技術。實際上,這個技術已經發展了有40年。這個技術的開端就是從1981年的夏天在MIT舉行的第一屆面向計算的物理學大會上開始。
這屆大會上出現了兩位從事量子計算的宗師,一位是大家比較熟悉的理查德·費曼,另外一位是保羅·貝尼奧夫,他們兩個人在這個會議上首次提出了量子計算機的概念。從那天開始,量子計算機就正式走入我們歷史的進程,所以才有我這樣的一個機會,站在這里跟大家講述。
根據我自己多年的科研經驗,我覺得,在量子計算這40年的發展歷程中分成四個階段。
首先在第一個10年里面,理查德·費曼和保羅·貝尼奧夫他們提出了量子計算機的概念,另外一個著名的學者叫David Deutsch提出了第一個量子計算算法。這第一個10年里,量子計算還是停留在理論的提出和探索階段。
歷史的車輪來到1994年。那一年,MIT的Peter Shor提出了大家熟知的Shor質因數分解算法。這是第一次在實際問題里面,展現了量子計算指數加速的效果。
從此,就開啟了通用量子算法發展的新階段。在這個階段里面我們有三個代表性的算法:一個是Shor算法;另外一個是Grover算法,清華的龍桂魯教授也在這方面做了一些貢獻;第三個就是線性方程組求解加速算法,我們簡稱HHL,是由MIT的三位學者提出的。
在這個階段里,由于算法加速的優勢,實驗物理學家也開始進行單量子比特和兩量子比特的物理體系的量子計算實驗驗證。
2010年開始,以谷歌和IBM為代表的企業開始進行規模化的量子計算實驗和工程化。這時候,大家發現,即使在含噪聲的中等規模的量子計算體系(NISQ)里面,又發現一些算法可以體現量子的優越性。它們就是玻色采樣、VQE(變分量子本征求解器)以及QAOA(量子近似優化算法)。
2018年至今,我覺得這是一個量子計算全新的令人振奮的階段——量子和人工智能相結合的爆發的階段。
提到這個階段,我們就不能不提像谷歌發布的TensorFlow Quantum這樣的架構。TensorFlow是谷歌提出在業內廣泛使用的深度學習的框架,它主動把TensorFlow和量子計算相結合。
這里面有一個非常著名的例子:在2018年,由谷歌研究員提出用量子門電路的一些參數以及量子測量打造的一個量子計算的神經層,跟經典計算的神經層相結合,通過梯度下降的優化,實現深度學習識別的算法,在小規模訓練中已經取得了不亞于經典神經網絡的計算的結果。
隨之而來的是,更多量子與AI結合的結果出現,包括QCNN(量子卷積神經網絡)、QNLP(量子自然語言處理),QGM(量子生成模型)等成果。
為什么我是覺得在AI時代更需要量子計算?
大家可以從這張圖看:深度學習自從提出以來,參數的規模是呈一個指數增長的狀態,右上角有一個大規模自然語音處理的訓練模型GPT-3,它本身有接近1750億個參數。這樣的大規模神經網絡是AI未來發展的趨勢。但它本身也帶來了巨大的算力、存儲、帶寬等問題。
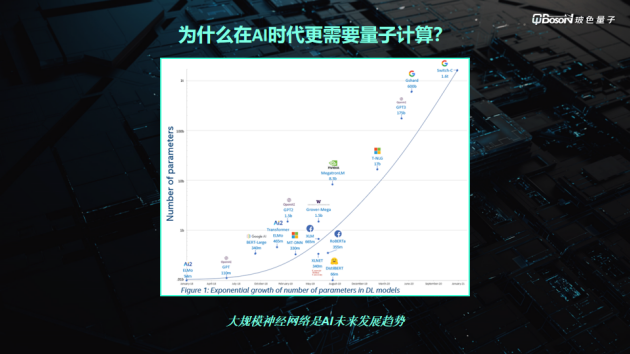
(AI時代參數規模呈指數增長/來源:玻色量子)
為解決這些問題,大家除了建造更大的數據中心,買更多的GPU顯卡以外,還在探索不同計算的路徑。我認為,量子計算所帶來的指數加速效果,實際上是一個很好解決大規模神經網絡運算的解決方案。
這里面我可以提出來新的指標。谷歌在2019年發表的論文已經解決了證明量子計算的優越性的問題。它通過50多個量子比特能夠替代超級計算機,在解決特定問題時要比經典超級計算機快非常非常多。
我們剛才提到的GPT-3模型,它里面有1745億個參數,每個參數是32位的單精度浮點。這么大的一個模型,在經典超級計算機里面用一張顯卡或者一臺機器是無法承載的。而在量子存儲器里面,利用用量子比特的疊加態,通過指數的疊加,其實只需要60個量子比特就可以完全承載這么大規模的參數。那其實就是量子在人工智能領域優越性的體現指標之一。
量子的優越性在人工智能里面分為以下幾個方面:
首先是算力優越性。量子計算通過量子的疊加實現了指數級增長,從而使得在神經網絡的訓練和優化里可以得到指數級加速的效果。
第二個是存儲的優越性。就像剛才提到的像GPT-3這樣的模型,它的參數可以用60個量子比特可以進行存儲,對于存儲空間是大大的優化。另外訓練數據不光是模型非常大,人類每天還會產生上百個PB以上的數據,這么大規模的數據如果能通過量子存儲器進行指數壓縮的存儲,那可以大大減少它們存儲的空間。
第三個是帶寬優越性。國家提出了“東數西算”的戰略,就是東部產生、存儲的數據,由西部進行運算。這會給東部和西部之間的數據傳輸的帶寬帶來巨大的挑戰。如果每天都要傳輸幾百個PB以上的數據,整個網絡帶寬是會面臨非常大的壓力。
在人工智能的神經網絡數據處理中,不光存在著數據中心之間的帶寬,還有機器之間的網絡帶寬,甚至在機器內部還存在著內存、總線以及線上緩存帶寬。這些都是一個未來潛在的瓶頸。因為摩爾定律CPU的算力在20年來已經有幾個數量級的提升,而帶寬經歷20年只有接近30倍的提升。隨著神經網絡規模的不斷擴大,網絡對帶寬的需求會逐漸變成一個很嚴重的瓶頸。
通過量子存儲器可以用少數的量子比特就能存儲大量數據,同時進行網絡訓練,這樣的話就可以從根本上解決帶寬的瓶頸。
第四個是在神經網絡里面有一定的魯棒性和容錯性。這樣帶來量子計算的好處就是在糾錯還沒有完全達到百分之百精確的情況下,我們可以通過神經網絡自身的一些魯棒性,可以去對沖掉量子計算自身的一些容錯需求。
最后我們也介紹一下在量子計算的三種不同實現的架構:

(面向神經網絡的量子計算架構/來源:玻色量子)
首先就是IBM在做的,基于門電路的通用量子計算設備。大家可以看到這里面最左邊圖,這是一個體積巨大的系統,采用了超導量子比特路線,需要在真空超低溫的環境下才能穩定運行。
中間這個圖是量子退火機,以加拿大D-Wave公司為代表。他們也采用了超導量子比特方案,也需要真空和超低溫,所以體積也非常大。在這些超導路線的設備里,需要超低溫和真空,不參與計算的能耗非常大。
而第三個是我們公司現在自主研發的相干量子計算設備。它專門針對神經網絡設計,是一種基于光量子物理實現的量子計算設備,在室溫下就可以穩定運行,所以不需要額外的制冷能耗。相比于前兩者,我們的方案在能耗應用比上就擁有了一個巨大的優勢。
玻色量子的口號就是“用量子重新定義AI”,實現用量子計算給人工智能帶來上述算力、存儲、帶寬、容錯上的優勢。我們歡迎各位海內外的專家、學者能夠加入我們,一起來開創量子AI的新時代。
 營業執照公示信息
營業執照公示信息